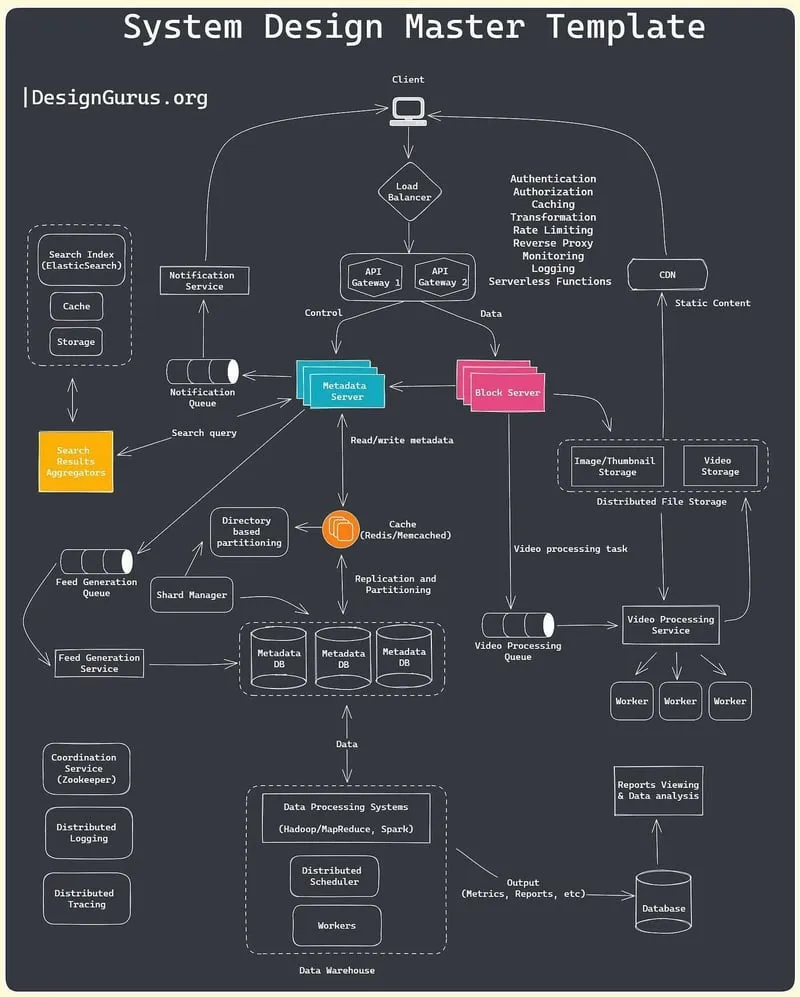
System_Design
Scale when needed, not because you can or it is popular this applies using vertical scaling first, until it is too expensive OR impossible(bandwidth)
Interview
-
always start with understanding problem and gathering relevant details
- relevant details: why we need this system, what functional will be included into system, requirements(functional and non-functional)
- functional requirements - describe what tasks system must perform
- non-functional requirements - describe how and on what constrains system must perform
- when stating some requirement, explain why it is relevant
- relevant details: why we need this system, what functional will be included into system, requirements(functional and non-functional)
-
define system constrains and estimates:
- estimate priority (reads OR writes)
- estimate number of: request per second, needed storage, bandwidth used
-
define large parts of system and broadly APIs, define each part of a system in details, refine and repeat
-
discuss bottlenecks and solutions
-
summarize the decisions with possible alternatives
- summarize the achievement of requirements
-
when considering if improvements to system are needed remember about:
- any change need to be justified by statistics
- how much money will be spent AND earned after improvement
all systems have several attributes, attached to them
- prioritizing one attribute might negatively impact other
- ex: more security == less UX
How to design
URL Shortener
- why we need it
- optimize link size
- hide original URLs (ex: affiliated links)
- track link performance
- functional requirements
- given URL service must return short/custom alias for it
- when alias is accessed, user is redirected to original URL
- each alias must have expiration time, with possibility to override it
- non-functional requirements
- high availability
- redirects must happen with minimal latency
- short links can’t be predicted
- extended requirements:
- performance tracking
- public REST API
- assumptions and constraints
- New URLs - 200/s || URL redirections - 20K/s || Incoming data - 100KB/s || Outgoing data - 10MB/s || Storage for 5 years - 15TB || Memory for cache - 170GB
- API
- Public API can be based on REST
- example of endpoint: alias, that will expose CREATE, PUT, DELETE, GET
- RateLimiting
- can be done per-customer, by API_DEV_KEY
- can be done per-api to prevent DDOS
- Public API can be based on REST
- DB Design
- notes:
- service is read heavy
- billion of records will be stored
- each record is small
- schema:
- user <- alias
- technologie: NoSQL
- reasons: low number of relationships, billion of records, easy to scale
- notes:
- Main algorithm variants:
- encode actual URL into SHA256(or similar) hash format + transform it to readable, fixed size string via Base64 + crop part of it
- 6 chars length is sufficient enough and will produce 64^6 variations
- problems:
- by slicing part of string repetition may occur - add shuffling to mitigate it
- same URLs will produce same aliases - add salting OR user metadata(performance impact)
- to mitigate uniqueness problem we need to add retries
- generate keys before-hand and store in DB, serve keys on demand
- benefits:
- easy, cheap and fast solutions, with no collision problems
- problems:
- concurrency
- move part of keys into memory and serve directly from there to avoid concurrency in-between slow calls to DB
- mutex OR synchronization is required
- single point of failure
- introduce replica
- concurrency
- benefits:
- encode actual URL into SHA256(or similar) hash format + transform it to readable, fixed size string via Base64 + crop part of it
- Additions:
- redirect is done via 302 (Redirect) response
- failing look-up should resolve into 404 OR redirect to default page
- we should allow custom aliases with more then 6 chars, BUT prevent too large strings
- redirect is done via 302 (Redirect) response
- Partitioning - to allow storing billions of URLs we should partition data, some variations can be:
- alphabetic range base - can lead to unbalanced partitioning
- hashing - with consistent hashing algorithm, to make partitioning balanced
- Cache
- tech: memcached OR redis
- how much: based on predictions it is enough to have one large machine, that will cache ~20% of URLs(hot URLs)
- but it is totally possible to have clusters of several machines
- LRU is great technique for high reads and storing only hot URLs
- if needed we can replicate our clusters
- each replica can populate itself independently via read-through approach
- Load Balancing
- it needs to be placed between: Client-Server, Server-DB, Server-Cache
- DB clean-up
- don’t serve expired links to users
- freed key can be restored keyDB
- cleaning strategies:
- separate light-weight service, that runs in periods of low load and clean expired data in batches
- remove on read request
- telemetry - can be implemented as separate service, with separate DB(for country, number of visits, user info, source of URL etc per-url) and be write focused(write-back technique)
- don’t forget to clear telemetry after some period of URL expiration
- it is possible to introduce user permissions per each URL
CDN
- what is it - geographically distributed network of data-servers, that has main goal to deliver data fast and reliable
- it caches content on edge servers(small server, that located as close as possible to client)
- why we need it
- reduce network latency
- load balancing
- remove single point of failure
- main components:
- client
- routing - distributes load, removes inactive sources from rotation, finds shortest route to the data
- API Gateway - rate limiting, DDOS protection etc
- proxy/edge services - serve content as close as possible to client
- here content is cached, to reduce number of requests to origin
- distribution system - sync content from main cluster with edge servers
- content optimization service - reduce size of data
- origin server - stores original content
- logging & monitoring
- management system - exposed part for user in form of public API (or web-app), that used for configuration, data management etc
- load balancing is placed between major nodes
- caching
- push - when new content appears, it is pushed from origin to edge
- pull - cache is updated on demand
- routing:
- how to find nearest proxy:
- network distance - shorter path + higher bandwidth == preferable proxy
- load - if edge is overloaded, request won’t be routed here
- ways to implement:
- DNS redirect
- anycast - all proxies will have same IP, while Anycast system will choose the most preferable one
- client multiplexing - establish multiple connections and serve content from fastest
- HTTP redirects
- to achieve higher speeds and scalability, routing can be done in tree like shape, with more efficient nodes(one or several of them) placed in the middle between origin and edge
- how to find nearest proxy:
- fault tolerance:
- if child fails - redirect client to other child
- if middle-man fails - redirect child to other middle man
- if origin fails - use replica OR, as last resort, serve content from middle-mans’ caches
- examples: Cloudflare, Cloudfront etc
Whatsapp (chat app)
- requirements
- functional
- conversations - one to one, group
- acknowledgment - track message status
- sharing - sending files(images, videos, audios)
- chat storage - messages should be persistently stored, even if user is sent them, been offline
- notifications - new messages should result in notifications
- non-functional
- low latency
- messages order consistency
- availability (can be compromised, if it will increase consistency)
- security - done via e2e encryption, where only people, that chatting, can see the contents of messages
- scalability
- functional
- high-level design
- userA establishes websocket connection with server, sends encrypted message to server, server acknowledges, server holds message until userB is online, server sends message to userB, userB acknowledges, server notifies userA that message is sent, userB reads, userB notifies server that message was read, server notifies userA that message was read
- data model design:
- users
- user_groups
- user_chats
- groups
- chats
- messages
- API:
- can be done via REST for broad support
- file upload can be done as two step process:
- upload file, receive URL
- share URL via message in specific format
- architecture: micro-services, because it is easy to scale and decouple
- low-level design
- users connect to WebsocketService, through load-balancer
- mapping and management is done via WebsocketManagerService
- WebsocketManager is connected to Redis cluster to store any needed data
- all messages can be retrieved from MessageService, that is connected to some persistence-first DB, like Mnesia
- it exposes APIs to manipulate messages
- it has auto-purging of historical data
- messages will be retrieved and stored in encrypted format
- all file operations are done via FileService
- compression and encryption is done on device
- blob storage is used to store files
- each file is tracked via public id(for sharing) AND via private hash(to avoid duplicated data)
- frequently used files can be pushed to CDN
- group messages can be routed to specific GroupMessageService, that will route it to Kafka. GroupMessageService communicates with GroupService to retrieve info about each group participant and sends messages to each user
- GroupService will have SQL-based DB, for ease of working with relational data
- this DB can be replicated geographically
- Redis is needed as cache here
- GroupService will have SQL-based DB, for ease of working with relational data
- users connect to WebsocketService, through load-balancer
- non-functional requirements achievement
- low latency
- CDN, geographical replication, caching
- messages order consistency
- FIFO queueing, acknowledgment mechanisms, persistence DB
- availability
- data replication, multiple load-balanced servers
- security
- e2e encryption
- scalability
- horizontal via micro-services
- low latency
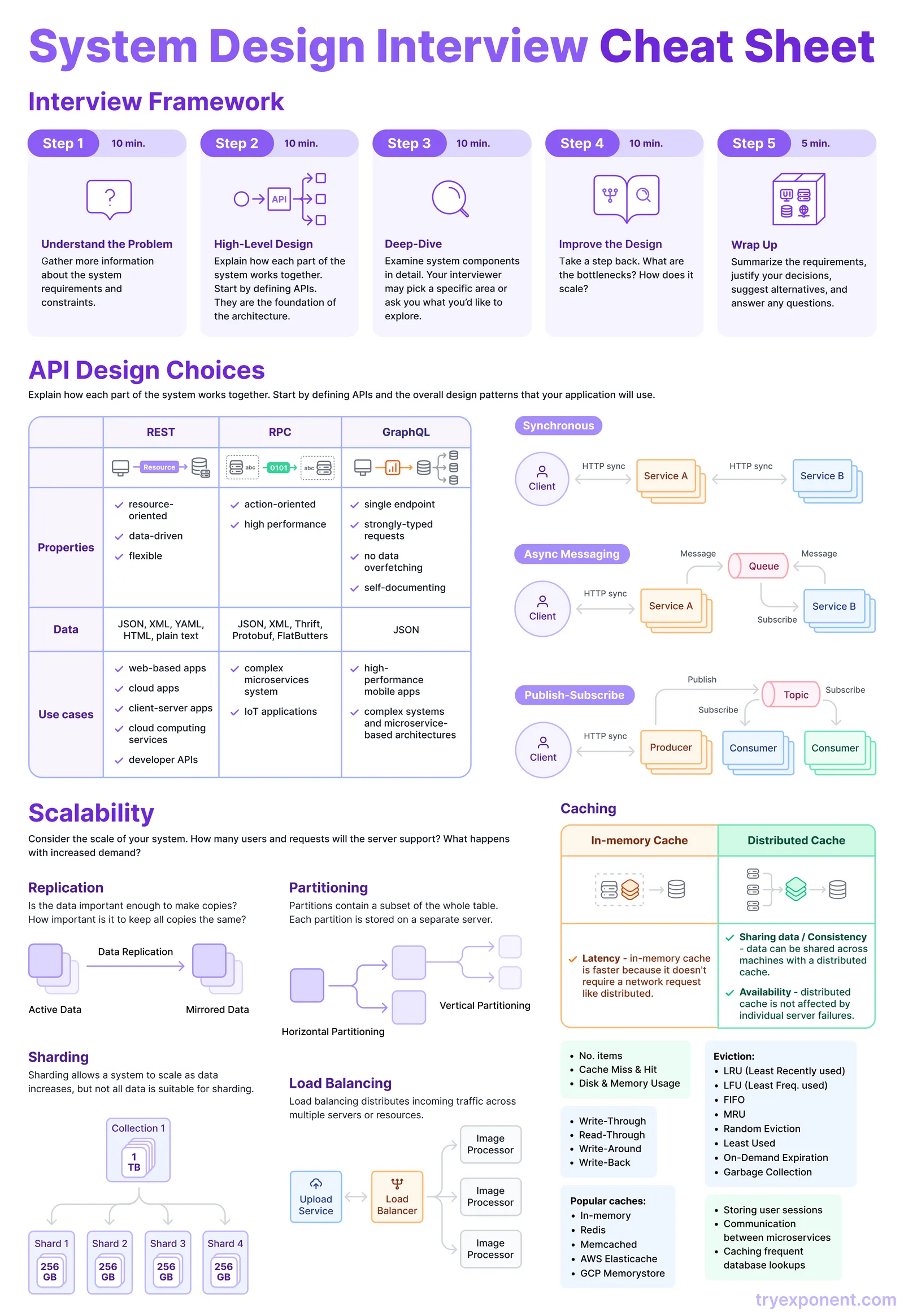
API Design
Describe how each part of the system works and why
Main Types
- REST
- flexible, data-oriented, has mass adoption
- JSON and text based protocols
- used for Web products, public/internal APIs, cloud apps
- RPC
- high performant
- JSON, protobuf(have lover support, because uses bites to communicate)
- used for IoT, microservice architecture
- GraphQL
- single endpoint, strongly typed and self documented
- poor performance, has security risks
- used for complex APIs
Communication Strategy
- sync - all requests done in sync, via HTTP
- async messaging - service post messages into queue and subscribe to it, to receive any response messages
- usually done in 1 to 1 manner
- publish-subscribe - service producer publishes messages into shared topic, services consumers can subscribe and receive any messages from this topic
- done in 1 to many manner
Scalability
Thing about how many users and requests system needs to handle. What types of this requests(reads or writes)
types:
- vertical - add more machine power for single machine
- horizontal - add more machines and distribute load
Replication
Process of copying data, that has several purposes:
- creating back-ups
- hosting data near locations of usage(US region, EU region etc)
Depending on purpose you need to consider several questions:
- is data need to be replicated?
- how often replications will happen?
- how accurate duplications need to be?
Partitioning
Process of breaking large DB into some logical parts, that will be stored on the same/external server, in order to make DBs more manageable, faster and more available
- the general focus of partitioning is to reduce cost of queering large data sets
examples
- introduce numeric ID per data-entry and partition by ranges
- partition by date ranges
- great for migrations, because you can migrate only relevant data and keep historical partially empty
types
- vertical - each partition will have subset of columns + some key to connect them
- great for splitting many columns and queering commonly used separately from less ussed
- horizontal - all columns stays the same, only rows are partitioned
- optionally, data is distributed across several independent servers
benefits:
- higher response times, faster reads-writes, higher availability
- faster maintenance(back-ups, migrations etc)
- more storage per partition
- several servers only
- outages are isolated
- several servers only
- access control per partition problems:
- introduces complexity
- higher possibility of errors
- poor and unbalanced partitioning will slow down system
- takes more space
Sharding
Type of horizontal partitioning, where we break large data into small chunks(shards) and store each shard/collection of shards in separate machines
To query data you generate and assign shard-keys per shard
- example: store users in shards, depending on their region, so all US users will be in US shard and all EU users in EU shard, thus making most of calls from each regions more optimized(request takes less time to travel), without overhead of full doing DB replication
- note: we aren’t accounting for number of users per region, thus US shard can be much larger and require separate sharding step, in comparison to Australia
great for dealing with traffic and data amount grows
Load Balancing
Technique to evenly distribute traffic amount several machines for efficiency benefits
use-cases:
- traffic distribution
- ensuring high availability by avoiding routing to inactive machines
- session maintenance
- SSL/encryption related operations
general approach is to take request and pass it to other machine, based on some algorithm, where algorithm can be:
- static - proxy requests, without consideration about current state of machines
- basically divide equally all requests
- easy to do, BUT will be less efficient, because some machines will become overloaded after some time
- dynamic - proxy requests, based on health(availability, load) of each server
- poll each server from time to time to receive it’s status and distribute load accordingly
- failover mechanism is needed, to reroute all requests from failed server to stable one
- harder to setup(each server must have endpoint to check it’s health)
- sub-types: by connection, by location etc
balancing can be used on the gateway to your system OR inside of it between servers and services
API Gateway
Technique to create single entry point to system, that can handle several functions:
- authN + authR
- caching
- request transformation + protocol transformation
- rate limiting - limit number of requests per some amount of time
- usually done by tracking how much time elapsed from previous requests from same IP(or by signing each request with some other metadata)
- response from rate limiter can be either 429(too many request) OR requests can be held in some queue
- routing, versioning etc AKA reverse proxy
- monitoring + logging
- serverless functions
problems to address:
- single point of failure
- as any single entry point to the system
- to address: replicate and load balance
- additional network overhead(risk of failing requests, requests take longer)
- raise of system complexity and additional maintenance
- security miss-configurations
Caching
Types
in-memory - data stored in RAM, so there is no need to add network overhead, BUT this way cache can be only local
shared - cache stored on separate machine, so it is accessible to all services
- cache is available, even if some service failed
- cache is consistent for each machine, so no need to create local caches
- problems:
- network overhead is present
Main terms
- number of items cached
- how much RAM or Disk Space is consumed by cache
- cache miss & hit - on way to measure cache effectiveness is to look how often we hit it, instead of going to DB or doing requests etc
Strategies
- write-through - data is saved into main storage + cache at the same time
- all writes are slower
- read-through - when request misses cache, cache holds request, auto-populates itself from DB and returns response
- non-cached reads are slower
- cache-aside - when request misses cache, system goes into DB instead, populates cache and returns response
- non-cached reads are a bit slower
- write-around - write requests are pushed into DB, data cached only after a number of read requests
- frequently accessed data is prioritized
- write-back - write requests are stored inside cache and unloaded into DB once per some amount OR time period
- writes optimized
Implementations
- in-memory - often via some libs or structures, like
Map - redis - robust, stand alone, in-memory cache
- memcached
- AWS Elasticache
- GCP Memorystore
Use-Cases
- storing user sessions
- reduce overhead of microservice communication
- caching frequent DB operations (reads OR writes)
Invalidation strategies
- time based - invalidate after some time
- types:
- time to live (TTL) - each data has some time, that it can live, after been cached, after which it will be refetched, if accessed again
- great for tokens
- types:
- event based - invalidate after some event occurs
- types:
- purge - remove cache
- refresh - invalidate cache and request new one
- ban - remove cache and stop caching
- stale-while-revalidate - serve cached versions, then update
- often used in CDNs
- types:
Cache eviction
Cache size is limited, so we need some method to make a room for new one, by efficiently removing other
- Least Recently Used (LRU) - remove last used data
- web pages in browser
- Least Frequently User (LFU) - sort data by frequency and remove one at the bottom
- search engine queries
- First in First out (FIFO) - remove data in order it was cached, similar to Queue
- messages in messaging app
- Most Recently Used (MRU) - remove first used data
- Random Replacement (RR) - remove random data
- data set with no priority between items, like assets in game
- Least Used - globally sort data by frequency and remove OR avoid caching ones at the bottom
- On-Demand Expiration - cache can be freed only manually
- the case, when managing in-memory cache in languages like C++
- Garbage Collection - cache freed automatically
- the case, when managing in-memory cache in languages like C++
Common problems
thundering herd problem - multiple cached items expired, thus all requests will miss and overload the system
- solution: warm cache in periods of in-activity
cache penetration - user DDOS service with non-existent data, thus preventing any cache hits and overloading the system
- solution: input validation, rate limiting of request
cache breakdown - cache breaks, thus all requests will miss and overload the system
- solution: implement failover and auto-recovery mechanisms, introduce health checks and system monitoring
stale cache - cache data is invalid, thus system operates on improper data
- solution: add logging to catch this issues, use stable technologies and patterns to avoid caching problems
Other concepts
Single Sign-On (SSO)
Tech that allows for user to sign once and access all parts of the system after it
- as benefit for devs, removes need to create separate authN flows per each app
can be detected by redirect to separate login page
implementation strategies:
- sub-domain + cookies - straightforward way, done by hosting all apps under single domain, thus allowing all of them to share cookies
- benefits: easy to implement
- problems: limited by sub-domain, specific implementations will arrive on each consumer, depending on their technologies
- separate auth service - create service that will be a single source of authN&authR truth
- implementation notes:
- based on token model(access + refresh), where token can be in JWT or some other hash format
- such token contains all info about user and can grant full or partial permission to system
- JWT (JSON Web Token) - format of encoding JSON into Base64 to transfer through net
- based on token model(access + refresh), where token can be in JWT or some other hash format
- benefits: cross-platform, one service handles all user & auth management, broadly adopted standard, user permissions can be granted partially(it can also depend on application, you logged in)
- problems: it is hard to recover lost token so additional safety measures need to be implemented
- implementation notes:
DB Design
SQL(relational DB) vs NoSQL(non relational DB)
Crucial point in DB design, is choosing what type of DB you need, based on your requirements and needs
SQL - focus on data with relations and column+row mental model
- have predefined schema
- can be scaled vertically and horizontally
- can be partitioned vertically and horizontally
- stores data in form of a table, with primary and foreign keys
- great for structured data, complex data, transactional data
- design is rigid, SO any change will require migration
- examples: PostgreSQL, MySQL
NoSQL - focus on flexible and dynamic data, with loose relations
- schema and types are dynamic
- can be scaled vertically and horizontally
- can be partitioned only horizontally
- stores data in format of a: document, key-val, graph; basically we can choose the most suitable format for data
- great for data like: documents, JSON
- can be easily scaled-up OR down
- data can’t be accessed in complex manner AND data normalization may be needed
- this leads to different syntax per DB
- no need for complex migrations, structure can be changed with ease
- can be great starting point, where requirements are loose and you need to change fast
- examples: MongoDB, Casandra, Redis
DB indexing
In general, index is a way to point to some information
- DB index have similar function and enabled faster read queries, because engine don’t need to scan full DB to find something, it can do scanning, based on indexes
- it acts as sort of metadata
types:
- clustered index - acts as primary keys for indexing
- changes order of data in DB
- data will can be stored as Balanced Binary Tree, thus enabling direct Binary Search on data
- can be only one per table
- changes order of data in DB
- non clustered index - acts as additional/secondary index
- doesn’t affect original data, BUT requires additional table to be stored, where it stores index + pointer to data location
- additional table can be stored as Balanced Binary Tree, thus enabling Binary Search on this metadata to find reference/pointer to original data
- can be several per table
- it is recommended to add indexes for most commonly used columns, when:
- filtering (
WHERE) - sorting (
ORDER BY) - grouping (
GROUP BY) - joining (
JOIN)
- filtering (
- doesn’t affect original data, BUT requires additional table to be stored, where it stores index + pointer to data location
problems:
- data modification queries are slower, because sync of indexing is required
alternatives to BBT:
- hash (don’t requires balancing, but won’t work for range quires)
- bitmap (great for read-heavy operations with small number of possible values)
sparse indexes - refer to partial data storage, meaning we index only some chunk of data
Proxy
Forward Proxy vs Reverse Proxy
Both proxies are important types and have distinct roles, main different comes from level of network operation
forward proxy - interface that client uses to interact with system
- use-cases: client anonymity(change client’s IP to proxy’s), caching, traffic control, logging, request/response transformation, authN&authR
reverse proxy - facade for single/multiple servers
- use-cases: server anonymity, caching, load balancing, DDOS protection, canary, request/response transformation, encryption/SSL management(offload servers)
- examples: Nginx
Serverless
Model of building backend, where all responsibility for managing server(env and machine) is offloaded to provider, so there is only need to write application code, that will execute logic and interact with simple APIs, from provider
- it is similar to Infra as a Service modal, BUT here you don’t need to do any management of infra at all
- also you pay per request AND NOT per machine
types:
- function as service - execute specific function in isolation
- backed as service - execute entire application
use-cases(often short lived tasks):
- API integrations
- trigger based actions
- schedulers
- notification sender
- webhooks
- automations
- data-processing
- backends (with low load on it)
benefits:
- auto-scaling, load balancing and other benefits are already done
- no need to manage any server infra, thus faster dev time
- pay per request
- language agnostic
disadvantages:
- you will go broke as your traffic grows ;)
- can’t execute for too long
- additional delay to spin-up
- vendor-lock
Authentication
Authentication can be done in different ways, where each way have some use-case, specific benefits and constraints
JWT (JSON Web Token)
JWT is way to encode JSON into binary format, so it can be easily transported
- it is not authentication technique by itself, BUT can be used to identify users in authN flow
- additional public/private encryption and/or hashing can be added for safety
- includes: expiration data, user info, issuer and additional metadata
- flow:
- client provides credentials
- server creates JWT, stores and return it to client
- client saves it somewhere(commonly in cookie OR in-memory)
- client adds token as part of request(usually as some dedicated header), so server can receive+verify token and proceed with request
- additionally:
- it is possible to have several tokens, for better UX
- session token - works as described above
- refresh token - used to generate new session token, without need to provide credentials
- it is possible to have several tokens, for better UX
- note: authR is managed separately and not a part of JWT
OAuth
It is a protocol, that enables authN & authR via/with third-party service(identity-provider)
- use-cases:
- give granular access for third-party to your service
- ex: allow service to edit user’s GoogleCalendar
- authenticate user into your service, based on data from identity-provider
- ex: Sign-in with Google
- this requires usage of OpenID Connect protocol
- for successful login identity-provider returns token, that can identify user in service
- give granular access for third-party to your service
- alternative: Federated Credential Management(FedCM) browser API
SAML (Security Assertion Markup Language)
XML-based standard of exchanging authN & authR data between parties
- flow:
- client provides credentials
- server creates SAML assertion in XML format
- client can re-use this assertion to authorize requests from itself
- common use-case: SSO
Related Algorithms and Data Structures
Consistent hashing - algorithm to evenly distribute data between multiple nodes
- implementation: for each node assign range of hashes, hash each data and assign it to node that covers value in it’s range
- additionally, it is possible to assign data and ranges to virtual nodes AND assign several virtual node to physical one, thus making down/up-scaling and data transfer easier
- use-case: DB partitioning
MapReduce - algorithm for processing large data sets in parallel, thus making it faster and reliable
- implementation is broken into several steps:
- break all data into smaller chunks
- map each chunk in parallel (result is often some key-value pairs)
- merge and sort all chunks together
- reduce result, so all keys are merged into one and each value is included in final result (ex: each value is summed, multiplied etc)
Distributed hash tables (DHT) - way to store data in key-value manner, so each pear of network can hold only part of data, thus systems becomes faster, easier to scale and more resilient in self-organization manner
- allows to locate value by only querying small number of participant
- enabled by proper distribution algorithm
- use-cases: p2p networks, CDN, distributed DB
Bloom filters - algorithm to efficiently detect if data is present in some set, by hashing and using bit map arrays
- can produce false-positive results, BUT with proper number of hashes and size of bit array, this rate is quite low, so can be tolerated, for large data-sets
Two-phase commit - algorithm to ensure consistent transactions in distributed systems
- flow:
- coordinator asks all nodes if they can commit
- if any answer is missing or “no”, operation is aborted
- if all answers are yes, operation proceeded
- coordinator asks all nodes to commit
- each node commits and sends status
- if any answer is missing or “failure”, coordinator asks all nodes to rollback
- if all answers are “success”, coordinator informs all nodes that operation is successful
- coordinator asks all nodes if they can commit
- problems:
- higher latency
- single pointe of failure
- dead-lock
Paxos - algorithm to ensure consistent values in distributed systems, with failure tolerance
- flow:
- coordinator asks all nodes to remember some value
- if majority answered - operation proceeded, else - aborted
- coordinator asks all nodes to accept some value
- if majority accepted - value accepted
- coordinator asks all nodes to remember some value
Raft - algorithm to ensure consistent stream of values in distributed systems, with failure tolerance
- flow:
- group of nodes elect the leader
- leader accepts the data and passed it to all nodes
- node can request data from leader too
- if leader fails, re-election happens
Gossip - efficient algorithm to share data in p2p systems, with high failure tolerance
- all data is transferred from node to it’s closest neighbours, thus populating network
- it can be transferred on demand (pull) OR when new data arrives (push)
CAP theorem - theorem, that states, that distributed system can’t achieve all characteristics simultaneously
- consistency - all nodes have same and up-to-date info
- availability - system is always responds
- tolerance - system is responds, even if part of it dies
Encryption
Symmetric Encryption
Method of using single key to encrypt/decrypt data
- this key can be viewed as a password, that need to be known by two sides beforehand AND can be shared at any point
Asymmetric Encryption
Method of using pair of keys to encrypt/decrypt data
- public key - used to encrypt data, can be shared
- private key - used to decrypt data, stays with party, that created pair
E2E Encryption
Method that encrypts data, to prevent any access to it, when it is transferred from one user to other
- it is encrypted on one side and can only be decrypted on other side
how it is done:
- based on asymmetric encryption
- uses insurance system, that prevents man in the middle problem
- insurance is done via legitimate third-party authority, that embeds keys into certificates
Transit Encryption
Method that encrypts data, to prevent any access to it, when it is transferred, but overall systems includes middle man, that encrypt/decrypt data, before sending it to users
how it is done:
- based on asymmetric encryption
- uses insurance system, that prevents man in the middle problem
- insurance is done via legitimate third-party authority, that embeds keys into certificates
Technologies
Redis
Redis is remote, in-memory NoSQL key-value storage, that is used as cache or lightweight and fast DB
- main goal is to reduce bottleneck of slow operations with DB or disks, by handling data in-memory
possibilities:
- in-memory cache
- queuing
- multiple data-types
- Sentinel - separate system, that used to manage distributed system of Redis instances for resource optimization and sharing
- Pub/Sub - separate system, that enables Streaming
- persistence - enables taking snapshots of data in memory and dumping them on disk
vs Memcached:
- benefits:
- allows for more data-types
- enables more fine-tuning of cache
- problems: higher complexity
use-cases
- DB caching
- real-time analytics
- location-based applications
Kafka
Kafka is used for decoupling data source from target system by acting as intermediate layer, that stores and enables data consuming
problems it solves:
- unify data formats
- unify transfer protocols
- reduce complexity, make system more maintainable and resilient
- allows handling high number of connections
specs:
- open source
- used as framework for storing, reading and analyzing data streams
- build to be horizontally scalable
use-cases:
- messaging - activity tracking — (working with streams)
- gather metrics, logs or any data from multiple sources
- stream operations
- big data
concepts:
- topic - temporal data storage
- partitions - each topic can be configured to be auto partitioned
- offset - ID, assigned per message, that relevant in scope of partition
- each message can be found with
topic+partition+offset
- each message can be found with
- broker - separate servers, that store partitions
- group of brokers == cluster
- replication - kafka can be configured to auto-replicate data to a given number of times
- separate partitions are replicated
- replicas will always be stored in other brokers
- replication is done via leader system, basically kafka has one leader, that performs read+write operations AND followers, that sync themselves with leader AND can become leader if original leader is failed
- producer - kafka uses load-balancers, called producers, that perform writes to leader partition
- all data is pushed to end of the topic
- algorithm: locate all brokers with leader partitions, choose the least loaded one, append data
- it is possible to provide key, that will be used to choose partition manually
- note: same key will always result in same partition
- it is possible to provide key, that will be used to choose partition manually
- data can be synced in this way(each has different risk of data loss):
- no acknowledgment - producer pushes data without waiting for any response
- 1-acknowledgment - producer pushes data with waiting for leader response
- n-acknowledgment - producer pushes data with waiting for leader and n-1 replicas response
- consumer - kafka uses load-balanced consumers, that read data from leader partition
- for better performance, consumers are packed in consumer groups, and read only portion of data from topic each(1 consumer per 1 partition)
- kafka maintain consumer offset - int number that points to last read data, so consumer won’t return duplicates
- consuming stratagies:
- at most once - message better be lost, than duplicated
- offset is changed after message is received, rather then processed
- at least once - message can’t be lost, but can be duplicated
- offset is changed after message is processed
- application must be idempotent
- exactly once - message can’t be lost and can’t be duplicated
- achieved via kafka-2-kafka streaming
- at most once - message better be lost, than duplicated
- consumer connects to 1 broker first, receives info about cluster, connects to other brokers(if needed)
- zookeeper - core software, that used to manage distributed system under the hood of kafka
RabbitMQ
For more robust and efficient service-to-service communications we can use Message Based communication, where each service interacts through a MessageBroker mediator
- improves speed
- reduces coupling of services
- allows for load-balancing messages to consumers
RabbitMQ is open-source MessageBroker
- most popular way of using is with Advanced Message Queuing Protocol, that sends data in frames in custom binary format
Concepts:
- producer - writer to MessageBroker
- consumer - reader from MessageBroker
- queue - intermediate storage for messages
- connection - RabbitMQ allows for TCP connections to it
- RabbitMQ establishes single connection, BUT it splits it into channels and uses them to send data
- exchange - receives messages from producer and pushes them to 0-n queues
- exchange configured via rules, called bindings
- exchange do routing based on binding AND received route-keys(addresses)
- types:
- direct - route to queue, by provided key
- fanout - route to all queues, specified in binding
- topic - do wildcard match between binding and key
- header - route by data in message’s header
- users - each instance of RabbitMQ includes authN and authR built-in
- each instance can be broken into virtual once
- acknowledgements - rabbit allows for loss free transfer via acknowledgement system(from consumer OR from exchange)
- acknowledgements can be batched
- prefetching - rabbit allows to set sliding window, of how many messages can be sent over one channel, before acknowledgement is received
- too high will cause overflow, too low will slow down transfers
best practices:
- keep queue size limited
- too large queue results in high RAM
- RabbitMQ has preserving RAM mechanism of flushes to the disk, BUT it will degrade performance
- how-to:
- limit queue size OR add TTL
- results in messages loss
- make acknowledgements fast
- they can be done in async manner, BUT it will result in messages loss
- limit queue size OR add TTL
- multiplex TCP + limit TCP connections
- keep connections long lived
- if loss isn’t and option, don’t limit queue AND enforce acknowledgements
- isolate consumer and producer with different connections, if done in single app
AWS Elasticsearch
Service for large handling operations on large data, such as searching, analytics etc
- can be self-hosted OR bought via AWS
- great for searching for data AND meta-data
In it’s core Elasticsearch works on top of large number of shards(small isolated DBs), and creates a facade with simple interface to query and operate upon those shards
- collection of relevant shards is an index
- upon facade it introduces replication mechanism
- highly performant, because utilizes indexes
- could be used as single source of truth
- have large number of data-types
Docker
Docker is software, that used to distribute other software
- based on containers, where each container is self-contained piece, that provides environment to execute anything inside of it
- characteristics: light-weight, flexible in customization, standardized(allows for ease shipping), self-contained(ease of deployment)
- main focus is to isolate piece of software and it’s dependencies, so it can consistently be ran in any env
- based in concept of Virtual Machine, which means some isolated environment, that simulates anythings needed and can be ran on shared physical hardware with other VMs or even full OS
- done by creating isolated instances of custom software + OS inside of it, putting them into actual machine, that has light-weight OS and hypervisor, which is used for monitoring, logging, managing resources, action taking etc
- plain VM is slow, because it needs separate full OS and vendor locked, because it is dependent on hypervisor
Docker combines VM and container approach, such as:
- each container has all needed code and dependencies
- software dependency is covered by using host’s OS
- Container engine allows hooking into OS with minimal risk
- concepts:
- Dockerfile - config with instructions to build DockerImage
- DockerImage - template, that contains everything needed and can be replicated into any number of DockerContainers
- each image is immutable
- DockerContainer - isolated container, that can be ran via DockerEngine
optimization tricks:
- cache is linear, so keep highly changing parts at the end of a Dockerfile
- aim to execute building steps for libs once and cache the result
Kubernetes
System, that built upon docker and used to manage large number of docker containers in configuration+automation manner
possibilities:
- ensure resilience, by re-starting failed container (failover)
- also includes health-checks
- scale containers up/down
- horizontal AND vertical
- deploy large number of containers with some deployment patterns
- automatic rollouts and rollbacks
- hosting container
- load-balancing is included
- environment, secrets management
12 factors of scalable service
- general requirements:
- building, starting etc of an app is done in declarative manner
- app is environment agnostic as much as possible
- app can be deployed in fast and continues manner
- app can be scaled without additional configurations
- grows of an app should be organic
- DX must be good
Factors
- Codebase
- all changes are tracked via VersionControl system
- notes:
- 1 codebase == 1 app
- several codebases == several apps (can be a distributed system)
- shared code should be factored to libs and used as dependency, NOT directly
- 1 app can have many deployments: prod, env(s), local
- deployments can be different version of an app
- Dependencies
- all dependencies need to be explicit and isolated
- implementations: system-wide, bundled into the app
- for dependency to be explicit and isolated it must be stated in some config/manifesto AND bundled into the app
- makes app easy to share AND all deployments uniform
- package managers are common tool for dependency management
- for dependency to be explicit and isolated it must be stated in some config/manifesto AND bundled into the app
- any “common” dependencies like curl should be bundled too, to be env agnostic
- Config
- config must be a part of the environment
- it can be accessed by an app from env OR it can be backed-in on the build step (if build is done in the env)
- it can’t be in the code, because it makes code differ per env
- config is one of few parts that differ between each deployments
- config includes:
- addresses to connect to shared resources
- credentials
- environment specific knowledge, like: hostname etc
- main goal is to make possible to open-source code and not leak any credentials
- this implies usage of standard processes, like
.envor similar systems, that prevent accidental leakage of credentials
- this implies usage of standard processes, like
- grouping configs will make scaling harder
- better way is to view each env as a thing on itself, that can be granularly controlled
- config must be a part of the environment
- Backing Services
- services can be
- local - hosted on same machine
- external - hosted over the net, on different machine
- any dependency in form of service(DB, third-party API, queue service, email service etc) should be tread as external, to keep any dependency easily swappable
- swap should be possible only by re-configuring envs
- services can be
- Build, release, run
- separate each stage of this process
- build - transform written code into executable, by merging-in dependencies, optimizing, compiling etc
- done by developers
- release - combine builded version and envs, with possible movement of code from machine to machine
- done by developers
- run - execute released version
- done automatically
- benefits:
- separation of concerns
- impossibility to un-build program, that is running
- possibility to re-use some step
- ex: make several runs from one example, create multiple releases from build
- possibility to rollback
- to do this you must: label each release with id/timestamp, keep all releases immutable
- Processes
- each instance of an app must be stateless
- all data must be stored in separate shared backing service
- any local state must be short lived
- ex: cache, intermediate values of operation
- reason: second request might be routed to separate process, process might fail, process might be re-ran
- Port binding
- all access to the app must be done via dedicated, opened port, by HTTP(S) or similar protocol
- the point is to make app easily accessible via single entrance point
- this allows to use app as Backing Service or directly asses it
- all access to the app must be done via dedicated, opened port, by HTTP(S) or similar protocol
- Concurrency
- scaling should be done via process model, where we have process formation, that tells us what types of processes do we have(ex: HTTP request handler, background task etc) and how much of each type we are running
- this way we can easily extract some process type into own machine OR reliably expand functionality
- process management should be done via standard APIs
- Disposability
- keep startup-ups fast and shutdowns graceful
- benefits:
- any changes can be deployed fast
- failed deployments can be re-deployed
- service can be scaled in both directions easily
- system can auto-scale
- system is more reliable
- notes:
- for web-sockets of long-polling seamless re-connect mechanism must be implemented on client OTHER requests must be short-lived
- for queue systems any unprocessed operations should be returned to queue
- for lock-based systems locks must be released
- incorporate sudden failure handlers to make unexpected shutdowns graceful-ish
- Dev/Prod parity
- keep dev and prod as similar as possible
- distinctions come from:
- time - feature is developed locally for too long
- use trunk based development
- personnel - deployment is done via DevOps team
- incorporate CI/CD
- developer need to verify that production is working and
mainis stable
- tools - different tools locally and on prod
- bundle dependencies into an app OR make it easy to run light-weight variation of dependence outside of an app OR expose environment dependencies for local use
- docker is often a great solution
- bundle dependencies into an app OR make it easy to run light-weight variation of dependence outside of an app OR expose environment dependencies for local use
- time - feature is developed locally for too long
- Logs
- logging is important for monitoring
- logs should be treated as stream of aggregated, time-ordered events
- logs can’t have beginning/end and often represented as txt with 1 log per line
- logs must be collected from each process and backing service
- app don’t need to know about logs
- general approach is to dump logs to
stdoutand make environment collect them to file, dump this files to some external storage etc- for local runs it is enough for dev to just see
stdout - external storage can be just archive OR some big-data service, that will allow to view trends, find specific events and add altering system, that will react to anomalies in logs
- for local runs it is enough for dev to just see
- general approach is to dump logs to
- Admin process
- it must be possible to do admin/management activities directly on prod
- ex: run scripts(ex: db migration), interact with live console
- scripts should be shipped directly with app’s code and can be treated as dependency
- direct access can be done with tools like SSH
- it must be possible to do admin/management activities directly on prod
Synchronization Methods
In system, where multiple operations can be done simultaneously, synchronization must be introduced
Mutex
Mutex is locking mechanisms, that provides ownership over some operation to single executor
Common principle, is to have moderator(mutex object), that can be locked and “held” by some party, until task executes. Other parties will wait, until mutex is locked. After one party finishes operation unlock call is executed and next in line can acquire mutex
-
use-cases:
- locking resource usage (data integrity)
- locking operation execution (no race conditions)
-
potential problems:
- some queueing should be held by mutex object, to avoid keeping one party waiting for too long
- prioritization can be added, to make higher-priority threads go first
- it can drain CPU
- if mutex wasn’t released, because process died, mutex won’t unlock and drain resources
- some queueing should be held by mutex object, to avoid keeping one party waiting for too long
how to deadlock yourself:
- make thread wait for release, when he is who one holds
Semaphore
Mechanism of coordination between multiple threads, that based thread-thread communication, without strict ownership
common principle is to have shared int value(>=0), that signifies how much threads can be used in a pool to operate on data. Each thread can Wait until value is >0, acquire slot by reducing value, do operation, increase value to release slot
-
pool manager need to give access to chunks of data per thread, to avoid sharing
-
benefits:
- multiple threads can work on shared resources
- flexible resource management
problems:
- risk of deadlock
- prioritization problem by default
- no modularity
Blob Storage
Blob storage is a type of storage, that is design to hold large amount of unstructured Blobs(Binary Large Object), that is basically data in any format, where each blob can be whole file(classical approach) OR part of file, that can be aggregated into whole file on demand
characteristics:
- has no structure
- should be scalable and have large capacity
- connectivity:
- via API for developers
- via CDN for users
- types:
- hot - fast access, hight price (often based on SSD)
- cold - slow access, low price (often based on HDD)
- data management:
- can include policies to evict data
- can have access managements
- can append metadata per blob
vs other solutions:
- file storage - has no structure OR hierarchy + doesn’t operate with “file” abstraction + uses bucket abstraction to store data
- block storage - designed as read-first + doesn’t support fast random access operations
common use-cases: file storage, log storage, CDN, media hosting, archiving
Block Storage
Block Storage is a type of storage, where data is broken and stored in fixed-size chunks(aka blocks), where each block has fixed address, so it is easily accessible
properties:
- data can be located easily, BUT has no structure as is
- no metadata is allowed
use-cases: OS, VM, DB, I/O heavy apps
M3U Files
M3U is file format, that defines what version of video OR audio do you have, so browser can look at it first, determine what version will be most sufficient to user(network, browser version, OS etc) and request specific media
Recommendation Algorithm
types:
- query based
- user + item properties match
- ---
- often they used hand-in-hand, by first filtering by query AND then sorting via match score
building an algorithm:
- divide into two modules:
- matcher - reduce initial data-set to what user might like
- ranker - rank reduced data-set
- non-functional requirements:
- large data-set: item data, user data, user-item interactions
- interactions can be collected in form of: user events(clicks etc), user actions(buy, like, comment etc)
- possibility to hot swap ML algorithm AND measure
- performance, auto-scaling etc
- offline training of ML algorithms via some data pipeline
- large data-set: item data, user data, user-item interactions
Designing Distributed Systems
Set of patterns and advices to make distributed systems efficient AND reliable
- this patterns aim to make development predictable and understandable, turning it from art to science
- basically, stop re-inventing the wheel each time
- all patterns are heavily based on Container pattern
Intro
Most of apps need to scale rapidly AND be reliable, thus there is only one way…build it distributed
History
Single purpose machines -> multi purpose, one task machines -> multi purpose, multi task machines -> network of multi purpose, multi task machines (client-server architecture) -> large network with single purpose (distributed system)
benefits of DS:
- resilience
- scalability
- easy to maintain(large organization with small teams, that own each MicroService independently) problems:
- cost
- hard to build & maintain
- hard to debug
The value of patterns
- patterns can be seen as best-practices, that can be re-used, to suite particular needs, without the need to re-invent the wheel, by spending too much valuable time making mistakes
- shared language
- each pattern can be seen as component, that can be combined with others to solve problems
Single-Node Patterns
Single-Node
Explanation: container - atomic part of DS, single machine - collection of one/several containers that can be viewed as one Node
Motivation
several containers per one machine have several benefits:
- cost reduction versus one container per machine
- isolation of resources
- each container can have limited resources of machine AND different priority to shared resources
- isolation of concerns - one container per one task
- in such way, you can build small tools(ex: sync local data with GitRemote), that can be easily re-used
- small services are easier to maintain, deploy, test etc
- team isolation - one container per one team
such tight group of several containers per one machine may be known as pod(Kubernetes)
- each container must be able to access shared resources
- deployment of all of containers must be easily done as single, atomic operation
Sidecar
Single-Node pattern, made-up from two containers: main(with application logic) AND side-car(extends possibilities of main container, without knowledge of it)
- deployed as single-node
- side-car and main share resource heavily
use-case:
- adoption of legacy code:
- add HTTPs to legacy service by proxying traffic through side-car to main
- add dynamic configuration to legacy service
- remember that app config should be easily backed OR accessible via API, so app is aligned with 12-factors
- re-usable utils:
- easily add health-checking system, by deploying side-car, that can read info from machine/process AND establish common interface to access this data
- alternative is to force each service to have such endpoint available
- problems: less tailored to specific needs, can be less performant
- such “utils” can be used to build event-driven modular services, that can perform configurable set of actions, when event occurs(ex: code is pushed into Git)
- easily add health-checking system, by deploying side-car, that can read info from machine/process AND establish common interface to access this data
good side-card must have:
- broad set of parameters
- it is important for all containers, BUT it is especially important for side-car, to keep it highly-reusable
- API
- ease of integration, ease of testing, lower risk of breaking-changes
- documentation
- can be done inside Dockerfile(
EXPOSE,ENV,LABEL(metadata, there are established patterns to use them))
- can be done inside Dockerfile(
Ambassador
Single-node pattern, with two tightly liked container: main(with main application logic), ambassador(communication middleware between main and external world)
- value comes from modularity and reusability
use-cases:
- storage sharding - with grows, you need to shard your storage, because single machine won’t handle all file operations
- problems: hard to integrate in system where other parts expect single interface to talk too, shards need to be managed, configuration is hard
- often solved with ambassador as service, where shard manager is deployed onto single machine and act as load-balancer, BUT we can use ambassador as container and put it in front of each service directly
- both approaches have tradeoff
- service broker - common problem in DS is service discovery(properly connecting applications with each other), service, that solves this problem is called service broker
- such service can be built with ambassador, basically your main connects to broker via localhost AND it is broker’s responsibility to find proper connection AND proxy requests to it
- blue/green, tee-ing AND other forms of request splitting for A/B testing purposes
- tee-ing is practice of sending request to old AND new service to compare results, do load-testing etc
- remember to keep your testing consistent per-user(keep some cache of who see what by IP)
- note: as other things, this can be also done on app level OR on separate service level
why not create ambassador as a service(tho this is valid approach too):
- service need to be scaled independently
- additional network latency
Adapter
Single-node pattern, with two tightly linked containers: main(application logic), adapter(modification of main’s external interface to meet some needs)
- value comes from possibility to unify needed parts of application, without the need to alter original application, where each app can be implemented differently, across the organization
use-cases:
- establish identical interface across DS
- ex: health-checks, logs, performance monitoring
why not include adapter into main’s code:
- reusability & modularity, because adapter is decoupled from main
- adapter helps protecting variations
- main can use 3d-party apps to do the thing
- BUT: if you can build your main with generic interface, you can, no need to create additional “custom” decision, that needs to be adapted
Serving Patterns
Serving patterns goes one level higher from Single-Node pattern, because now we are operating on Service level, where each Service is independent machine(Single-Node)
- each Service is loosely coupled with each other
- communication is done only via network(some defined API) AND can be parallelized
- Serving Pattern is based on Multi-Node systems, aka MicroServices
- notes:
- communication is always done via some API, BUT it can be: sync OR a-sync(stream based, queue based)
Replicated Load-Balancer
Comes from two parts:
- Stateless Service - service, that can operate with little-to-no internal state
- pros: can be scaled horizontally AND don’t need state maintenance, makes system resilient
- ex: API Gateway, CDN etc
- notes:
- to achieve resilience you always need to have AT LEAST 2 replicas, to have some time to do roll-outs and roll-backs + other can be scaled-up, if needed
- Load-Balancer - service, that routes incoming requests to Services behind it
- types:
- StickySession
- reasons: higher cache hits, requirement to maintain state between requests
- problems: horizontal scale AND resilience are partially lost
- to partially make-up for that, introduce consistent hashing
- notes:
- can be done via IP or Cookies or Fingerprinting
- Randomized - requests from same user can be routed to different machines
- requests are distributed equally:
- can be done statically OR with heal-checks, to determine if service keeps-up
- requests are distributed equally:
- StickySession
- notes:
- each service need to have a notification mechanism, that it is up and running(readiness probe)
- when doing Randomized type, you will have lower cache hit rate, BUT you can make-up for that, by moving cache from memory, to Cache as a Service, and going there first
- you will have higher hit-rate, BUT slower operations, because of network overhead
- basically, you always want a number of small application instances AND couple of large cache instance
- load-balancer can become API Gateway, with adding more functionality to it, like:
- rate-limiting
- as a pattern, you can give restricted access to anonymous users AND large limits to logged-in users
- don’t forget to do proper
429response with header, that indicates when next request is allowed
- SSL certificate change
- use-cases:
- remove encryption on API Gateway and do internal communication via HTTP
- remove public encryption AND add internal encryption to do internal communication
- ideally each service must have uniq certificate
- note: you can use custom certificates for internal usage AND specifically signed for public usage
- use-cases:
- rate-limiting
- types:
Sharded Service
Similar to replicated service, BUT each shard can process only subset of requests, thus more sophisticated Load Balancer required(in such context called Shard Manager) AND we can work with stateful services
- use-cases:
- break large DB, FileStorage or Cache into smaller, more manageable once
- break large game-server into several smaller once AND shard by player locations
Distributed Cache
- why sharding - to increase processing capacity, without decreasing overall hit-rate
- why cache is important:
- increase in capacity of the system - cache can increase number of requests system can process, because you don’t need to count cache request as request processed by the system, but only by the cache
- ex: 50% cache hit rate will double the amount of RPS your service can process, BUT putting max_limit as double is not ok, because failure in cache OR in shard of cache will lead to overload
- decrease in latency - cache will always be faster than actual calculations, so average response time is faster
- remember, that depending solely on average value is dangerous, because if cache or it’s shard fails, requests can pile up in queues AND break the system
- remember to load test with AND without cache
- notes:
- when increasing number of shards, cache will degrade for a bit
- replicating shards might be a good idea
- this will allow for safe rollouts AND prevent “hot shards” problem, where some shard receives more load, because it’s content is popular at the moment
- alternative is to design overall system resilient to cache failures, which is not always an option
- increase in capacity of the system - cache can increase number of requests system can process, because you don’t need to count cache request as request processed by the system, but only by the cache
Sharding Function
- characteristics:
- uniformal distribution
- deterministic result
- choosing the identifier:
- characteristics: stable
- examples: request path, entity ID, geographical location
- notes:
- if several IDs used in to find shard, you need to find their hashes separately AND by both hashes find shard, not calculate combined hash
- implementations:
- hashing function
- algorithm: transform some identifier in request to integer hash -> modulo hash value by number of shard -> route request there
- problem lies, when re-sharding needed, because this will produce to large number of request remapping AND will lead to partial/full cache failure
- consistent hashing - solves re-sharding problem
- hashing function
Scatter/Gather
Pattern, that enables processing of requests in parallel, by breaking request into small, independent once, processing each part in parallel and combining into whole answer again
- you can view it as sharding of computation resources, rather then data sharding
- Root can also dynamically measure how each Shard responding AND load it more/less
- similar situation can happen, if you have initial large data-set, that need to be calculated-upon on demand, BUT is impossible to hold in one machine
- basically, Root will route request to each Shard, each Shard can process only part of data-set(no risk of duplication), Root aggregates responses into large Response
- note:
- MapReduce is great algorithm for some Scatter/Gather use-cases
- when it comes to scaling number of Shards, remember about bottlenecks like: network, processing resources of Root, struggler problem(final time will equal to speed of slowest Shard OR if one Shard fails, request fails)
- to make system more resilient, replicate each shard
Event-Driven Processing
FAAS (function as a service) is popular name for Even-Driven Processing pattern, which basically is an alternative to long-running servers, that have state, can perform long-running computations etc
- basically, FASS is short-lived service, that is triggered by event, spins-up, do some work and spins-down
- note, that serverless is kinda similar to FASS, because serverless is about operation without personal server, so FASS can be executed with such model in mind, BUT FASS can also execute on your machine
- please, don’t use it as one fits all solution ;)
- BENEFITS // DX, auto-scaling, auto-recovery, high modularity(FASS is even more atomic then container)
- PROBLEMS // hard to debug, no local state/cache, network overhead, self-DDOS, won’t work with long running OR background processes
- always remember to include monitoring in such highly-modular system
- it is costly, so, on scale, it is better to just use classical server OR self-host open-source FASS solutions
- patterns:
- Decorator - take request, transform, pass along
- use-cases: handling async-events
Ownership Election
Ownership in Single-Node system is easy, there is one node, that owns somethings, BUT for scalability we need replication, thus a way to establish ownership
- generally we operate with Master and Slave naming, where replica cluster has single Master, that is a main owner AND other replicas are Slaves, that can be elected as Master by some election protocol
- side-note: ownership election is only needed, for distributed systems with replication mechanisms
- remember that such systems have pros and cons, so it is important to decide is it worth the money, maintenance issues etc
Sharing resources
One approach to build distributed system, is not even elect Master, it is to share resources, which is done by locking mechanisms: Mutex, Semaphore
- note, locks are usually used inside service and implemented with some primitives, that manipulate shared variable, BUT locks for distributed systems are done as shared key-value store
- in distributed system process might file AND not release the lock, so some TTL timestamp is needed, that will perform release after expiration
- add some mechanism, that won’t allow replica to unlock the lock after TTL expired OR crash the service after TTL, if it is appropriate
- if needed, we can add renew mechanism, that will allow holder to renew TTL value and continue holding the lock
- mainly used, when ownership is needed for whole duration of service life
- such long-running locks MAY resolve in concurrent behavior, where timeouted holder, for short period of time, beliefs that he is still holding, SO we need to store hostname of actual holder AND add validity checks, that will be performed by workers, who receive requests from replicas
- due to network, it is possible that order of requests can be mixed in such way, that lock won’t prevent it, to mitigate you need to add version to request itself AND add validity check to worker
Batch Computational Patterns
There are cases, when you need to process large amount of data in short-period of time, so patterns for that arrived
- mainly speed is achieved via parallelism
- ex: video processing, data aggregation, report generation etc
Work Queue
Main idea of WorkQueue is to have independent tasks, that need to be executed within some time-period
- such tasks are placed on queue, grabbed by Manager and passed to workers
- workers can be scaled-up/down on demand to meet expectations
- note that we can extract generic queue logic from application specific part via ambassador pattern, so we can plug use-case specific ambassadors, when needed
- general fact, when establishing API between those to, always add version for future-proofing
- when engineering Worker it is best to work with file-api, because you can generalize process of downloading and passing file to some black-box(script) AND then sending outputted result back to the cloud
- general algorithm: load available work -> determine state of each item -> spawn workers to process unprocessed items -> mark item as processed on finish
- autoscaling must rely on average time to process item AND average time when new item arrives
- in order for system to keep-up you need to process faster, that things arrive
- processing faster, makes it possible to deal with bursts of traffic
- in order for system to keep-up you need to process faster, that things arrive
- if you need to stack operations(ex: detect object, blur object), it is better to create Worker Aggregator, that will implement single Worker interface, BUT under the hood delegate to two workers
Event-Driven Batch Processing
Event-Driven Batch Processing aka Workflow is basically stands for multiple Work Queues, that pass result of one Queue as input for another
- in it’s simplest form, triggering Event is end of one process and data passing to other one, BUT it can be more complicated
- ex: you need to wait for two queues to output, so results are merged simultaneously in the next Queue
- it is something similar to event-driven FAAS
pattern:
- copier - duplicate single input into same output, but multiplied
- filter - filter-out Batches, that don’t meet some criteria
- it can be as simple as putting Ambassador onto generic queue
- splitter - split evenly OR by some criteria single input into multiple outputs
- merge - combine several input flows into one flow
we can hand-craft some event system, BUT it is better to use pattern of publisher-subscriber, where we have some Publisher, that adds Messages to Queue AND Subscriber, that listens for new Messages in queues, grabs and processes them
Coordinated Batch-Processing
Coordination is basically a continuation of Event-Driven Batch Processing topic with focus on how to actually aggregate/merge several parallel results
patterns:
- join - wait for AND combine set of inputs into single output
- remember, that it will reduce parallelism AND make things slower
- reduce - similar to join, BUT here we performing some operation, as well as joining, that will reduce data set to some other data
- reduces can be chained, so we still have reduced parallelism, BUT not as much as join