FrontEnd
Internet
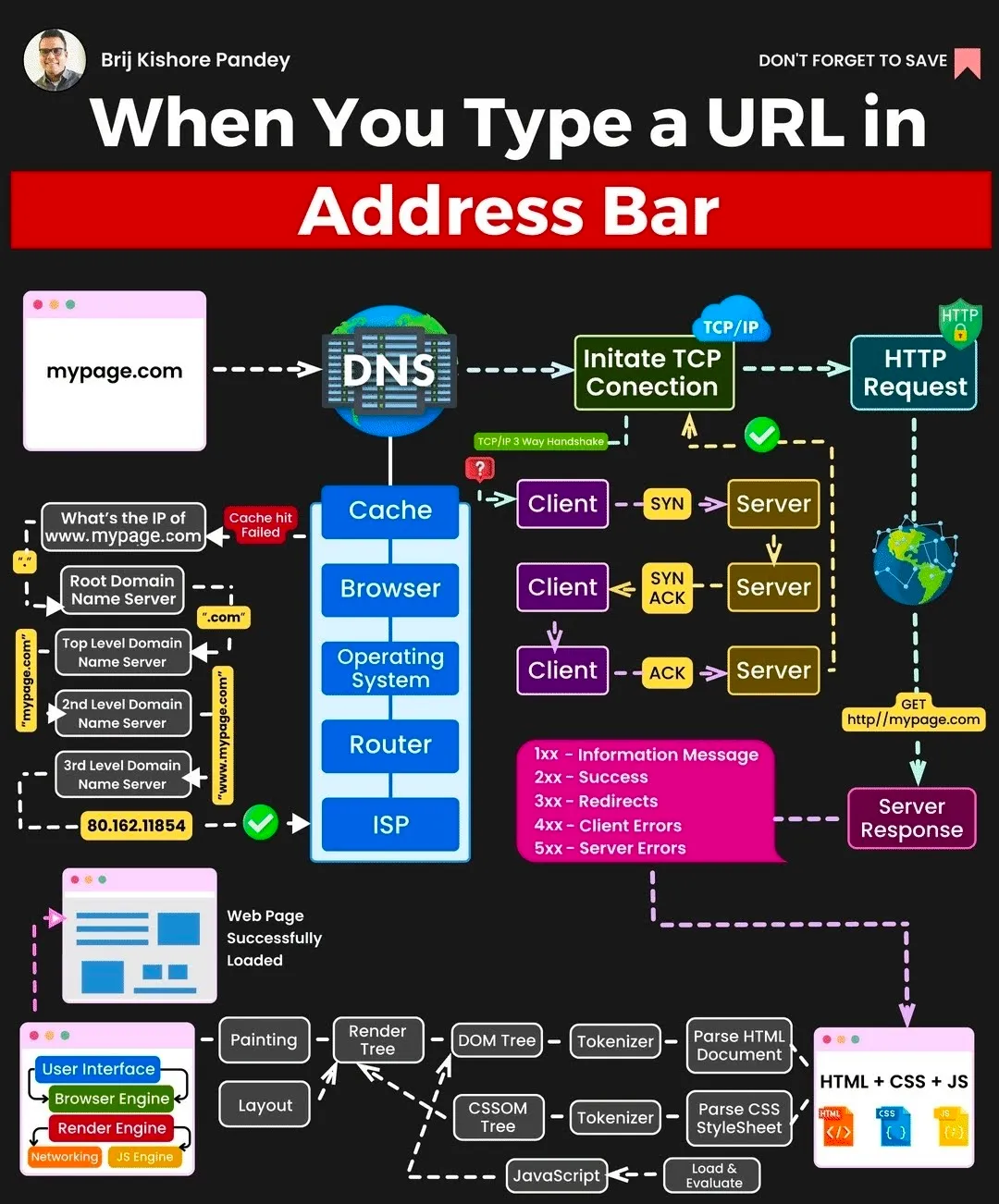
Browser Process
- Parsing
- HTML
- parse, convert to nodes, build DOM tree from nodes
- CSS
- parse, build CSSOM tree
- HTML
- Rendering
- after HTML and CSS finish parallel parsing they combined into Render Tree
- render tree is similar to DOM, but without(
meta, script, link, display:none) AND with(:before, :after)
- render tree is similar to DOM, but without(
- Reflow/Layout
- layout - first iteration, other repetitions - reflow
- build layout tree that is handling all elements/pseudo elements positioning
- this process is handled by traversing Render Tree one/multiple times
- changes of css will case Reflow
- reflow can be done to part of tree OR all of it
- it is better to reduce unused css and deep of tree for optimize
- (partial list)
.getBoundingClientRect(), .clientLeftand other JS operations can cause reflow- Reflow is done inside main thread(Event Loop) so it can be blocked
- Paint/Repaint
- paint - first iteration, other repetitions - repaint
- traverse layout tree and add color, bg etc
- repaint triggerred by reflow, css, js
- if it is animation all repaint+compose calculations are done via GPU
- Composite
- break all components into layers, rasterize, combine layers
- done in separate thread
- broken in tiles with priority to visible elements
- LAYERS
- transform, opacity, will-change properties move elements to separate layers
- after HTML and CSS finish parallel parsing they combined into Render Tree
OSI Model
abstract network model for developing and communicating through network
- application
- client-server communication
- presentation
- compression + encryption
- session
- queue of data transfer
- handling client-server connection
- transport
- used to handle which app is getting request by port(1-65535)
- some of ports are reserved
- used to break data to packets, check if data received fully etc
- based on TCP/UDP
- used to handle which app is getting request by port(1-65535)
- network
- used to complex data addressation via ip address
- ip address - logical address that linked to device by network admin
- some are reserved or may need to be registered
- 0-255.0-255.0-255.0-255 (32 bit)
- routers can be admins, that handle inner requests and outer request
- they have two ip addresses: inner and external
- all nodes are filtering out requests if they know nothing about receiver
- ip address - logical address that linked to device by network admin
- used to complex data addressation via ip address
- data link
- check if data transferred correctly
- usually by checking control sum
- data transferred by small frames with linked meta-data
- handle paralel data transfer
- handle data path by mac address(xx:xx:xx:xx:xx:xx
base16)
- mac is linked to device on manufacture stage
- switch, bridge
- check if data transferred correctly
- physical
- transfer data between machines
- hub, repeater, modem
this model can be compressed to TCP/IP stack(layer - protocol):
- application - http, ftp, dns etc
- transport - tcp, udp
- network - ipv4, ipv6
- network interface - ethernet, wifi
TCP
Transmission Controll Protocol
- establish connection
- 3 way handshake(want to connect - agree, want to connect - agree)
- transmit data with confirmation
- STANDART TCP: send data(try again if no answer) - check if data transferred correctly, send that data received with next part of data that need to be received
- Cumulative TCP: send bunch of data at once
- close connection
- close - closed + close - closed
UDP
User Datagram Protocol(DNS is based on it)
send request(repeat if no answer) - receive answer
faster, but can loose some data(good for video/audio stream)
HTTP(S)
Hypertext Transfer Protocol (Secure) used to transfer HTML, JSON, other data
message
- types: request - response
- STRUCTURE
- method - version
- path - status code
- version(1.1, 2, 3) - text status
header(meta data)
- key-value
- host - required header
body(optional)
HTTPS
data is encrypted via TLS(SSL before) protocol
this protocol is done by system of public keys, certificate etc
REST
general rules how to implement API interface
methods
- GET users/ - User list
- GET users/:id - User details
- GET users?name=alex - filtered User list
- HEAD users/:id - similar to GET, but don’t responds with body
- OPTIONS users/ - returns all headers that can be configured
- POST users/ + body - create new User
- PUT users/:id + body - fully update User
- PATCH users/:id + body - partially update User
- DELETE users/:id - delete user
status codes
- 1xx - info
- 101 - switching protocol
- 2xx - success
- 200 - OK
- 201 - created
- 3xx - redirect
- 301 - permanent move
- 304 - not modyfied
- 4xx - client error
- 403 - forbiden(auth)
- 404 - not found
- 5xx - server error
- 500 - internal server error
- 503 - server unavailable
API
API(application program interface) - interface to interact with program
Work with designer
Main points
- auto-layouts
- designer must use padding/gap instead of manual centering
- colors, fonts and sizes are based on predefined design system
- changes should be shown by comments
Animations
- lottie-web
- designer makes animation for some object and send it as ready to use json
- framer-motion(react)
- library of ready to use animations, that designers can choose from and devs easily implement
Accessibility
Accessibility in web is big topic that includes(sorted by priority):
- keyboard controls
- elements must be selectable by tab, forms submittable by enter etc
- it is possible to make div natively selectable, but recommended to use only native tags(a, button, forms, inputs etc)
- screen readers(there are different types of them)
- huge part of this topic is semantic elements, elements that have predefined meaning
- historically
divandspanis used as main building blocks, but they have no meaning to screenreader and other devs, so there are number ofHTML5elements, that work like containers(sometimes with special properties), but with this semantic meaning <article>- independent peace of content, that can be understood by it’s own- post, comment etc
<aside>- some content, placed aside main content- table of content
<details>- additional details, that can be hidden like accordion<summary>- used to define always visible part of<details>
<figure>- self contained content, like illustration, image(s), diagram, code- usually used with
<figcaption>, that is semantic description of a<figure>- placed as first or last element of a block
- usually used with
<footer>- bottom part of webpage, that includes contact info, navigation etc<header>- top part of webpage, that includes headers, navigation, logo etc<main>- main part of webpage<mark>- highlighted text<nav>- major block of navigation links, that contains hyperlinks inside<section>- some content grouping, that usually has a heading<time>- used to wrap a time text- can contain any data, but if it is correct time value, it will be localized by screen reader
<dl>+<dt>+<dd>- description list element, that is used with description title and description description to implement a glossary like structure
- historically
- huge part of this topic is semantic elements, elements that have predefined meaning
- reduce monition, dark/light themes
- low quality screens
- colorblindness(contrast issues)
- gestures
- optimization for cases where no JS has loaded
accessibility must be firstly included in design
there some countries(EU, USA etc) with laws that obligates webpages to have certain level of accessibility
SEO (Search Engine Optimization)
helps to fool search engine
main ways to improve:
- time that user spends on page
- how people got to page
- green lighthouse
<meta> tags are mostly needed for bots and not SEO
SPA is bad for SEO, so SSR is used(when we send HTML + JS that makes it work)
SSR (Server Side Rendering)
we render HTML on server and send it along side with JS that makes it “alive” based on hydration methods
improves SEO, accessibility
good for open resources, but sucks for CRUDs
Hydration
Island
Frameworks
React native
converts react components to native IOS/Android elements (realizes bridge pattern)
cons:
- still slower then native, because of JS layer
- for full native app simulation you may need to setup DB
- hard to manage navigation
- you often can have edge cases, so Swift/Kotlin may be needed anyway
use-cases:
- to develop MVP
Electron
not a framework, but a tool to convert existing web app to native desktop app
breaks into two parts:
- chrome instance with more rites that browser to render
- node.js server to work with OS
- both parts are communicate via post-messages
cons:
- hard to update(similar to other desktop apps), so you need a dedicated server to control versions + update btn somewhere
- slower and not as good as native
use-cases:
- fast and cheep web to desktop app conversion
- ATM “OS”
LocalStorage
store data scoped by domain
- pros: native, easy to use
- cons: sync, slow, small storage size, sereallization dependent(stores all data in string)
alternative - IndexedDB(modern browser API that gives you way to work with DB via JS objects and built-in methods)
SessionStorage
same as LocalStorage, but scoped by tab+session
Cookes
similar for LocalStorage, but used for client-server interactions
- often set by server and can be modified/seen by client
can be set to expire
Virtual tables/lists
In order to render huge amount of data via list/table you can use virtual technic(by lib or custom one)
For lists you are doing local lazy loading(render data partially) + set some huge hight, relative to array length, so you can have native scroll
GraphQL
Way of client-server communication for complex-aggregated requests. Basically introduces it’s own language to create requests
Huge step in client-server communication evolution
- introduced Query-Mutation separation to front-end
- inspired react-query
pros:
- strictly typed
- easy to use on front-end
- great for BFFs
- however, bff can be built to return prepared aggregated entities without GraphQL cons:
- heavy requests are hard to restrict
- auth(mostly fixed)
Web…
WebAssembly
Tool to connect any language with web
pros:
- heavy calculations can done on client cons:
- not really useful
WebGL
Tool to pass heavy rendering to GPU
ThreeJS is based on it
Can be used for cool 3d websites, casinos/other games, retail stuff(3d models of furniture etc)
WebC:
Tool to pass calculations to GPU
Can be used for AI and stuff :)
Internationalization(i18n)
i18n - short version of internationalization
i18n is deep theme, that includes
- translation
- data-time
- different variations of same language
- design
- right to left
- overall page layout(example: in Japan layouts are more cluttered then western)
- and many more
Translation
good process:
- systematic
- easy, fast, async
- automatic
- l10n with context(screenshots etc)
- no monkey job
Translation management system(TMS) - system for translator to work with translation, that integrated in development
- manages translations similar to git(push source, pull translations)
- can be integrated with CI/CD
- have translation memory(saves all previous translations, so you don’t need re-translate prev knowledge)
- tools: Crowdin
one of the best localization frameworks: LinguiJS
- easy work with plurals
- eslint integration
- universal
- rich tooling
- lightweight
- compatible with international formats
- tags(like links) can be part of translation
Shadow DOM
Shadow DOM is part of DOM, that is used for creating parts of component, that can’t be affected by CSS or JS from regular DOM
- element can’t be:
- queried from JS
- styled by CSS selector
- etc
Basically we are having a shadow DOM root, that points to shadow tree, that will be joined with regular DOM on render
Shadow DOM is used to create incapsulated object, meaning we can manipulate Shadow DOM as regular DOM from inside of it, but can’t interact from outside or with outside DOM
JS API
const root = document.querySelector("#root");const shadow = root.attachShadow({ mode: "open" });const span = document.createElement("span");
span.textContent = "Shadow DOM";shadow.appendChild(span);mode: openmakes our component open to use from JS viaroot.shadowRoot- it is not strict(extension can break it) and more like recommendation
HTML API
<div id="root"> <template shadowrootmode="open"> <span>Shadow DOM</span> </template></div>- everything in template is not visible by default, so we are using
shadowrootmode - on render,
templatewill be replaced with it’s children, creating correct DOM structure
To style we can use JS like this:
const sheet = new CSSStyleSheet();...shadow.adoptedStyleSheets = [sheet];Or add <style> inside <template>
Or add link to external style-sheet
- note: stylesheets won’t block render of shadow root, so un-styled element may appear on screen for some time All in all, this styles will be scoped to this Shadow DOM
Often use-case is creating custom elements, with some inner workings, like this:
class Circle extends HTMLElement { constructor() { super(); } connectedCallback() { const shadow = this.attachShadow({ mode: "open" });
const circle = document.createElementNS( "http://www.w3.org/2000/svg", "circle", ); circle.setAttribute("cx", "50"); circle.setAttribute("cy", "50"); circle.setAttribute("r", "50"); circle.setAttribute("fill", this.getAttribute("color"));
const svg = document.createElementNS("http://www.w3.org/2000/svg", "svg"); svg.appendChild(circle);
shadow.appendChild(svg); }}
customElements.define("filled-circle", Circle);<filled-circle color="red"></filled-circle>yep, I was pretty shocked too
Creating custom elements
Custom element is element that extends some predefined element, with added behavior by developer
two main types are:
- customized built-in element - extends behavior of existing element, like
<p>etc - autonomous custom element - extends from
HTMLElement, and fully implements needed behavior - note for framework devs:
- both patterns are appliable to react(or smth else), where second is standard approach to creating components(but without need to implement
HTMLElementinterface) and the first is mainly used when creating custom elements lib, where you can create some highlight element and extend<mark>element props + pass it like this to main element:{...rest}
- both patterns are appliable to react(or smth else), where second is standard approach to creating components(but without need to implement
CSS API
:define- matches every “defined” element:host- matches host of ShadowDOM style is used:host(selector)- same as:host, but with possibility to pass another selector as parameter:host-context(selector)- matches all host’s ancestors via selector:state(name-of-internal-state)- match custom state
API
- both types are done as class, that
extendsneeded interface, withconstructor, that callssuperconstructorcan also add some event listeners, init state etc, BUT not interact withchildren,tagsand break some other requirements- this interactions can be done in lifecycle callbacks - functions, that browser calls at specific moments
- so smth like react-classes lifetime methods
- this interactions can be done in lifecycle callbacks - functions, that browser calls at specific moments
- lifecycle callbacks
connectedCallback- called, when element is added to the document- used for most setup purposes
disconnectedCallback- called, when element is removed from documentadoptedCallback- called, when element is moved to new documentattributeChangedCallback- called, when attributes are changed- takes
(name, oldVal, newVal)parameters - it is used in combination with
observedAttributes: string[]static property, which states, what attributes we need to observe- example:
static get observedAttributes() { return ["color", "size"]; }
- example:
- cb will be called, when DOM is inited, so it is safe to do attribute related setup here
- takes
- registering step is done by calling
window.customElements.define(name, constructor, { extends: "tag" })- name is usually lowercase with hyphen
- extends is used with customized built-in elements
- usage is done by:
- using
isparameter for customized elements:<p is="some-name"></p>
- using element like element for autonomous elements:
<some-name></some-name>
- using
- custom CSS selectors(only for autonomous elements)
- CSS allows to react to custom properties, similar to
hoverand others via:state(name-of-internal-state) - to make it work we need to implement it via JS like this:
- call
this._internals = this.attachInternals();inconstructor, which makes element reachable from CSS and addthis._internals.statesto interact with it - note:
stis not visible from outside - add getter and setter, that interacts with states
- call
- CSS allows to react to custom properties, similar to
get st() { return this._internals.states.has("st");}
set st(flag) { if (flag) { this._internals.states.add("st"); } else { this._internals.states.delete("st"); } }Web Components
WebComponents is a term, that includes several technologies, that allow creating reusable components with encampsulated logic
Basically it is emphasis on DRY in native web, without custom UI render mess
Main pillars are:
- custom elements - reusability of component
- shadow dom - markup, style and script encapsulation
- HTML templates - creating some structure in HTML, that won’t be rendered into the DOM
<template>- used to:- declaratively create ShadowDOM, if has
shadowrootmodeset to proper value- there are also other properties, including
shadowrootdelegatesfocus, which allows to click on any part of shadowroot and delegate focus to first focusable element inside of it- this will also focus parent element
- there are also other properties, including
- create HTML, that can be later cloned into DOM somewhere else
- basically more declarative way of constructing HTML via JS
- there is a pitfall to woking with
DocumentFragment, when we appending it’s clone, we are actually appending it’s children, so it is important not to add handlers etc to fragment itself, caze they aren’t passed over
- declaratively create ShadowDOM, if has
<slot>- element, that can be later filled with some markup, aka separate DOM tree- it has
name, that acts as ID and can take some placeholder as children - to use fill it, we need to pass element as child to our web component with
slot="name-of-the-slot"and now this element is “slotted” to needed place- note:
<slot>without a name will take all top level children of component, that don’t haveslotattribute
- note:
- it can be useful as a pattern for rendering async data(for example, it can take
<loader-component>as placeholder)
- it has
Basic flow of implementing web component:
- create a class for custom component with needed functionality
- register custom component
- attach ShadowDOM if needed
templatewithslots can be attached here too
- use in markup, as regular component
Web APIs
- Storage - used to store data(
key: string-value: stringpairs) in browserlocalStorage- stored data have no expiration time and will be kept, until smth/smb will clear itsessionStorage- data is stored in scope of one tab- closing tab or browser will erase data
- refreshes will keep data
- generally more efficient and have more space, compared to cookies
- WebSockets - used for bi-directional communication between client and server over single TCP connection
- gives low latency and high speed, by excluding need to send new requests
- main use-case - data streaming
- connection is stable, guarantees data consistency and order(there are nuances, when used with Promise API)
- Server Sent Events (SSE) - used for one way(server to client) communication in form of events
- similar to WebSockets, but for one-directional use-cases, such as push-notifications etc
- basically client creates
EventSourcewith needed URL and server send formatted stream of responses
- Service Workers - used as a proxy layer for network
- use-cases: offline-first app, caching
- basically ServiceWorker is registered onto page and, after that, can control all it’s requests(event in background)
- Location - used to determine user’s location(if permission is granted)
- use-cases: maps, location sharing, working with location specific data
- it is also possible to do calculations and subscribe to location changes
- Notifications - used to send notification into system level(for example from browser to user’s phone)
- as many others requires permission granting
- done by creating
Notificationobject- it is possible to customize title, body, icon, actions etc
- Device Orientation - used to access data about orientation and other motion data(pitch, roll, yaw etc)
- use-cases: motion controlled games
- if permission is granted, it is possible to read to react(via events) to change of parameters
- Payments - used as standard flow for checkouts, collecting payment or shipping data etc
- used by creating
PaymentRequest, triggering it, when needed and receiving data from user- this enables GooglePay like payments, were you can click button and payment modal will appear
- PRACTICALY: may be not always useful, but great source for inspiration
- only with HTTPS
- used by creating
- Credentials - used as interface for getting/retrieving emails, passwords and other tokens from/to user
- only with HTTPS
- Auth - used to work with non-default auth methods, like PassKeys
Architecture on FE
Architecture is a way to define general shape, guidance and structure to for application OR even system
- architecture includes principles
- every architecture is basically about system parts WITH system characteristics WITH decisions AND principles
Architect must be as close to developer as possible
- still you need a way to verify that your architecture is implemented by devs
- architecture must be based on business needs
Laws:
- everything in SE is trade-off
- if you have no trade-offs, you just didn’t found one
- why > how
- Hyrum - with sufficient amount of users, any observable behavior of system will be dependent on, despite the contract
- All systems tend to denormalization, so we need to avoid speeding-up this process and enforce opposite via rules
Main problems:
- Scale
- Quality
- Performance
- Risks
- Role erosion (keep FE responsibilities in strict boundaries)
Ways to keep project maintainable:
- keep concerns separated AND interfaces between them clear
- keep state local
- composition > inheritance
- DI
- keep features close to one each other
- infrastructure things must be generic and adapted for app needs
- refactor early and iteratively
- keep application layered
Notes:
- each decision will have impact in long run, SO some decisions should be evaluated and agreed upon
- write ADRs to make decisions and preserve them for future read
- main structure: Context, Decision, Rationale, Status, Consequences
TS Patterns
- benefits:
- tight feedback loop
- self-documented code
- autocomplete
- combinable with JS
- superset of JS
- problems:
- build step
- vendor lock
ecosystem:
- compiler
tsc(typecheck - compilation)- there are
tscalternatives, BUT with only compilation - can be used for project OR for single file with passed config as file OR as CLI params
--noEmitwill just check types- note that default
tsconfigis bad AND better use some opensource variant - create different
tsconfigs for different tasks (tests, node, browser etc)
- there are
- tsserver - IDE integration OR done as plugin to work with TS autocomplete system etc
- eslint plugin for TS for additional strictness and typesafety
TS operates with concept of assignability
- B is assignable to it’s superset OR equal to it set, BUT not to subset
TS has structural type system
- differently named
typedeclaration will be considered equal, if they identical type-wise - to mitigate this you can use branded type, which in some implementation may look like this:
type Brand<K, T> = K & { __brand: T }AND be used to differ between type-wise similar, BUT logically different types (ex:user.id: stringandorder.id: stringare logically different and can be branded accordingly)
rules & recomendations:
- bad code can’t compiled
- type inference is great, so utilize it
- keep code type-safe by utilizing build AND runtime checks (parsing & validation)
- use existing libraries for “well-known”, but not built-in types
- research types of your libs
- don’t use:
any,Function,Object,String,Number, and{}for type-deffs- exception for
anyis(...args: any[]) => unknown
- exception for
Notes:
- valid JS is valid TS, every error is just “lint” error
- TS allows to pass union key into object and receive union type of it’s values
- enum should be defined as key <-> string for clarity and to avoid nuances
- sometimes it is better to use strings
- discriminated union can’t have
undefineddiscriminator OR several discriminators - avoid
anyin favor ofunknown- external data source should be validated first
- TS allows to do type narrowing via: type guard fn (return
boolean) OR assert fn (returnvoid | never) throwANDtry/catchhave no types, so use error as values where it is suitable (functional libraries can help here)
Browser Internals
Browser is an app that’s main purpose it to enable interaction with web
- it’s main task is to render HTML+CSS pages and execute JS code
- browser orchestrates number of processes, from interactions with it’s UI to page rendering etc
- each process is separate thread
- each tab & iframe is separate process (parallel)
- rendering overview
- get html, css, js, etc (network process)
- build DOM + CSSOM trees
- done on-fly, while fetching data from network
- parse & execute blocking JS
- use
asyncordeferto prevent blocking
- use
- build final render tree
- calculate computed styles and form final document styles
- form layout tree
- form paint records
- composite & rasterize (separate GPU thread)
- all elements are grouped into blocks to avoid re-rendering blocks, if their content wasn’t changed
- display
- critical blocking code is css and js in
headelement - to run JS code you need env (HTML page, worker thread) & engine
- env will provide isolated execution with separate heap, stack, queue, global var etc
- engine provides thin execution layer with general heap and stack
- V8
- simple flow
- parse code
- build AST
- interpret
- run on CPU
- compile
- run on CPU
- ---
- interpreted and compiled code both can be ran on CPU, it is just generally slower to do compilation, BUT, if code is often executed, you can gain performance boost, because running compiled code is faster
- also you might need to run interpreted code due to loosey nature of JS
- most of values in V8 managed by pointer, except small ints
- this most operations are done on heap
- V8 reuses same strings to reduce RAM usage
- to avoid manual memory management V8 removes unused heap memory via GC algorithm (mark-sweep)
- there are two algorithms, fast and slow to partially and fully clean memory (young objects AND old objects with fragmented memory)
- basically we try to kill object, if it survives we copy it to old memory region, BECAUSE most of data will die young, but old living data probably will live quite a will, thus we don’t need to re-check it often
- fresh memory has low fragmentation, unlike old one
- there are two algorithms, fast and slow to partially and fully clean memory (young objects AND old objects with fragmented memory)
- simple flow
- event loop - a way to parallel single threaded app
- not part of ECMA, but still part of JS ecosystem as part of Node.js and browser
- queues
- task: JS parsing, HTML parsing, events, CBs, resource loading, reaction to DOM manipulation
- non-FIFO queue
- micro-task: Promises, MutationObserver, queueMicrotask
- used mostly to implement ECMA restrictions for Promises
- FIFO
- task: JS parsing, HTML parsing, events, CBs, resource loading, reaction to DOM manipulation
- basic flow:
- get oldest task from Tasks (first one will be to parse & execute sync code)
- execute task
- clean Microtasks
- new microtasks will be executed in current iteration, so be careful not to block yourself
- run rendering
Basics of Functional Programing
functions
- pure - has no side-effects, timeouts and/or state
- always have same output for same input
- benefits: testability, simplicity, less bugs
- to achieve we often use immutability concept, by copying data and not modifying it
- testability, simplicity, possibility of time travel
- first-class - function works identical to value (can be saved, passed as param etc)
- high-order - accepts or returns fn
functor - somethings that can store value AND have method, that allows to operate on it’s values (by creating copy of operation result)
- functor must provide value retrieving operation
- utilizes chaining of operations in form of pipelines
- allows to declaratively describe data flow
monad - functor with additional operations:
- pack value into monad
- unpack nested functors to flatten structure
- examples:
- Maybe - nothing OR value
- Either - error (left) OR value (right)
- benefits:
- side effects encapsulated
- same interface for different cases without imperative checks
- data pipelines
- testability
pipe - get array of functions and call one by one passing result of prev to next to avoid nested fn calls
libs: ts-belt
Security & Secure Coding Practices
FE is real attack vector that must be properly handled
Cross-Site Scripting (XSS)
- classic - use unsafe user input as HTML for other users (risk of injecting script)
- avoid using pure input from user OR do clean-up, validation & stringification
- often handled by modern frameworks
- still avoid direct html manipulation and
unsafeHTMLusage
- still avoid direct html manipulation and
- modern variations
- injected data into emails
- injected data into query params
- ex: get param and do redirect
- what can be done with XSS:
- session tokens
- redirects to fishing pages OR injection of fishing forms
- keyloggers OR extension data stealing
- what can be done to prevent XSS:
- never trust user input
- validate, filter
- avoid untrusted libs
- do ecranisation
- avoid direct injection of HTML
- at least use lib to encranise your injected data
- use as less external data as possible
- avoid direct injection of HTML
- use Content-Security Policy (CSP) to avoid external scripts (so even if XSS happened it can do nothing)
- CSP is based on zero-trust principle, when we trust nothing, except specifically stated thing
- can be done via http headers OR via tags
- allows to granularly restrict srcs for: scripts, styles, images, iframes etc
- to safely work with inline scripts you need to utilize hashes of inline-script code (additional CI/CD & client load with risk of breaking already deployed scripts, if script changes) OR via Number Used Once (Nonces) (SSR only), which is uniq identifier per script, generated by server
- CSP can do auto-reporting of blocked resources for visibility
- with possibility to do reporting only without CSP blocking
- use CSP evaluator from Google to validate your CSP
- never trust user input
- notes:
- avoid unsafe state exposure (query, localStorage etc)
- XSS can happen in different variations (
scripttag, html tags that execute code, svg with executable code etc)- alway validate inputed files
Prototype Pollution - vulnerability that utilizes JS inheritance nature by swapping parent methods to custom one to be later called from your code
- be careful when working with object parsing from net
- to prevent:
Object.freeze
Supply Chain Attacks - dependency is a risk, so it must be managed properly
- vectors:
- packages
- pin versions & use lock files
- use as least dependencies as possible
- and only trusted once
- always do audit (native AND/OR via external service, that also might check your code for dependency)
- developer fishing
- issue tokens with lowest privileges
- CDN
- avoid using external CDNs as much as possible
- use Subresource Integrity (SRI) to check hash-sums of files
- CI/CD
- packages
- it is problematic, because poisoned dependency can target anyone:user , dev, CI/CD, server; because dependency is ran on all of those devices
- watch what package you install
QA
- quality - when product does what we expect it to do OR is result aligns with requirements
- every business has goals, that form product needs, that implemented via some goals, which can be described through func (business needs) or non-func (constraints, quality attributes) requirements to form some result
- developer must assure proper requirements and proper quality, so result is properly aligned with business
- when developing something you need to have some Software Development Lifecycle, where you do: analysis, planning, architecting, development, testing, integration, monitoring & support
- shift QA left and do it as early as possible (focus on product and requirements) (reduces cost of mistake)
- shift QA right to convert it to AQA (health-checks & auto-tests) (scalability)
- QA can be done by dedicated person OR by dev
- QA can be viewed as domain expert
- QA should become as part of definition of done
- QA must be measured (coverage etc) and have quality gates (CI/CD, heath-checks etc)
- most of QA is done in Agile way, for flexibility reasons
- QA is mostly about process, that done by each team-member
- everyone is responsible for quality
- designer can do testing as well (you can even automatically send screenshots of UI to designer for verification)
- always collaborate with peers when testing
- testing types:
- TDD
- behavior-driven testing - write test based on user behavior
- mutation testing - change your code and detect if tests are failing
- property-based testing - test with randomized input
- code review
- infra testing
- linting
- black & white box testing
AQA & Debugging
- It is cheaper to write E2E test, rather then unit, because you need write more of them, do mocking and consider implementation
- integration tests can have more than one, logically relevant, asserts to reduce test setup & boost performance
- to run tests in debug mode you can use extension OR open debug console & just run your test
- vs code only
- in
vitestyou can avoid directly mocking values and just usespyto infiltrate original fn behavior- don’t forget to reset and restore mocks
vitest&playwrightallow to write customtestfns, that will have dependency as properly, thus you can once write setup & destruction and then re-usetestwith fixtures auto-passed to ittest.extends- it works in inheritance + functional style
- this is clean, easier & more optimized (fixtures created on demand) then
beforeEach&afterEach - fixture can use other fixture
playwrighthave defaultpagefixture to work with browser
vitestallows to generate & later compare snapshots, generated by functions, to do snapshot testing- playwright allow to do screenshot testing
- better to dockerize such tests, to avoid problems with different UI per different OS/env
- playwright allow to do screenshot testing
- to use external dependencies in
vitestyou can use testing container to dockerize your app and bake-in dependencies - debuggin
- you can log from dev tools via “add log point”
- you can overrider original code with some modified one via
network.overridestab- even better solution is to overrider network requests via Wireshark or similar tooling
State Management
common state problems
- props drilling
- too much unstructured setStates
- state sync & management issues
- useEffect dependency issues
- performance issues due to too much state updates & re-renders
- working with network & forms
zustand
- based on atom concept
- utilises Signal pattern
- has concept of store, but, unlike context, it will trigger granular updates of UI
state architecture patterns:
- flux - data change in one direction, via actions+dispatcher+store (Redux)
- can be quite slow
- declarative style
- history revind
- atomic - data changes granularly, in small atoms, based on Signal principle, when we subscribe to atoms and change them (Zustand)
- more imperative, BUT better observability of state usage
- can be proxy-based, when we hide Signal logic inside proxy of object in JS (MobX)
- observer pattern - state changes in reactive way (RxJS)
- might be powerful for some cases, BUT also quite complicated
- declarative manner
- local first - data lives on server, BUT can be accessed+modified locally and later automerged with conflict resolution
- similar to flux pattern, but has sync engine to do BG synchronization
- results in sync code with all server operations ran in bg
- quite complicated
notes:
- be careful with keeping logically similar state splitted (ex: two network call to receive data + some calculations over data)
- this could lead to inconsistent state
- you can have several context provider to have DI
- be careful with Context, it triggers global re-render, BUT it is great for tightly coupled components, tightly coupled components OR for passing dependencies
- keep states separated:
- server state - tanstack query
- stable state - context
- global state - zustand/redux/etc
- local state - useState
- url state - router
- state normalization is keeping state structure plain (state.user.tasks -> state.user + state.tasks)
API Integrations
- RPC (Remote Procedure Call) - way to describe communication in form of calling external methods
- most popular framework is gRPC
- has built-in streaming
- has gRPC Web protocol to work with browser
- you need to use envoy, connectRPC or similar tooling to convert gRPC <-> gRPC Web
- uses Protobuf spec to define contract
protocwith plugins from vender (often connectRPC) is used to transpile it to TS OR just via Buf- we need to index fields to avoid sending full field names via network
- binary based, BUT can be wired via JSON too
- to debug binary, use special browser extension
- connectRPC is kinda it’s own protocol, that can be used with gRPC, gRPC Web, allows to do binary streaming and overall has nice browser integration
- use when you need realtime communication, need optimize client/server communication
- most popular framework is gRPC
- GraphQL - way to communicate in form of data queries (data is represented as graphs)
- great for multi-platform
- useful for complex data structures
- SSE (Server Sent Events) - native to browser way to do streaming over http from server to browser (text only, we need to keep http connection always open)
- WebSocket - protocol for bi-directional (channel won’t be blocked by any event) communication with possibility to use binary data
- flow: ask server for websocket connection -> change connection type to WS
- better to use with some lib (often provides: fallback to short-polling, retries, reconnects etc)
Bundle, Build & Deploy
bundlers:
- dev run (with ESM for optimization)
- transpiling (JSX -> JS, TS -> JS etc)
- import aliasing
- you can also do import restrictions via linting
- code splitting
- note that if you need to support long sessions you need to keep N previous releases & error detection that will ask user to reload too stale session
- source maps
- avoid keeping source map open to public
- envs
- analyzers
- constantly analyzer bundle structure, splitting, size & lighthouse metrics
- minificaiton & tree-shaking
DevOps & CI/CD
DevOps is like QA, while it is often a separate position, this is also often about culture an process of development & delivery (ideally automatic) of changes
- includes: automatization, CI/CD (similar to DevOps, but about practical things and tools), cooperation inside team, monitoring, culture
- ideally DevOps must be kept as code OR config files (Pulumi, Terraform) for testability, traceability, ease of change etc
tooling:
- cloudflare (CDN, DNS, SSL, file storage, firewall, zero trust solutions)
- kubernetes - platform to enroll containers (often via Docker)
- includes: API GW, Reverse Proxy, services etc
- monitoring & alerting
- canary & blue/green
- metrics
- tracing in-between requests via ids
- logging
Performance
Don’t focus on performance for sake of it, if you have problem/requirement, measure & find weak spots AND only than fix
Browser is doing layout etc in same thread as JS execution
- in some cases browser can even pause sync code execution to do something more important
Basic debugging of performance is to look what takes too long to load & what takes too long to execute
- to reduce load:
- reduce static files size
- use compression
- reduce dependencies & use tree-shaking
- code splitting & lazy loading (load only critical CSS & JS)
- minification
- different image sizes per device
- pagination (network & server load reduction)
- prefetches
- CDN
- keep content closer to user
- reduce own system load & complexity
- global caching for popular resources
- optimal network usage (client can have only 6 connections with single server)
- to reduce number of requests
- sprites instead of small images
- bundling (often we have some common bundle + dependencies + one per page)
- caching
- GraphQL, RPC OR, at least, thin requests & responses
- inline critical CSS & JS (be aware that we can’t cache it properly)
- reduce number of server redirects
- filters & paginations
- to reduce execution time:
- avoid blocking operations
- multithreading
- defer/async
- optimize code
- reduce DOM manipulations
- when doing manipulations prefer transform & opacity
- reduce number of blocking requests to server (if possible, load things granularly with preloaders)
- preload, preconnect & prefetch
Design at Scale
types of webpages:
- award winning, often single use, pages that made for marketing & just to be impressive
- service - long-living things, that bring value to user (need to be simple, understandable, properly designed (with design system) & have good structure)
- funnels - landings/quizzes that try to get user to by your product
- treat them as products, optimize & do A/B testing
design systems - collection of colors, fonts, sizes, components, spacings & grids etc
- main point of debate with designer (after decision is made, you will just use it)
- you can view system as collection of atom (single unit of design) -> molecules (abstract rules around atom usage) -> organisms (simple components) -> templates (combination of components) -> pages
- design system is based upon ui kit, that have main fonts, sizes & colors with their description
- keep coded design system in storybook
accessibility (mainly used for gov sites, but also great to integrate everywhere)
- optimize for screen readers
- use WCAG rules checker to measure somethings like contrast
notes:
- design is subjective, so use objective metrics like user satisfaction, conversion etc to estimate it
- use animations & microinteractions for better UX & more understandable UI
- don’t overuse animations
- some animations can be done via JSONs (lottie) OR simplified by libs
- do mobile first
- find references & adapt them fro your cases